|
About VirtualGL Developer Info
Library Related Projects |
VirtualGL BackgroundIn the early 2000's, thin client computing was a marketing buzzword-- something that excited the people in the main office but something that organizations didn't really know how to leverage effectively. Today, it stands poised to be the next sea change in the IT industry, driven in no small part by the advent of mobile devices and cloud-based services. For applications that demand a great deal of system resources and deal with very large amounts of data, the ability to run those applications remotely from the "cold room" has been a desirable -- even necessary -- feature for quite some time. Even for less heavy-hitting applications, thin client computing allows large organizations to significantly reduce their IT expenditures by way of a less complex administration model, improved security, and reduced hardware costs. Moving graphics into the cloud is the last step toward achieving a fully virtualized, location-independent computing environment. However, whereas a host of commercial thin client solutions exist to turn run-of-the-mill desktop applications into on-demand services, most of those solutions either lack the ability to run 3D applications or force those applications to perform 3D rendering without hardware acceleration. Most of the existing solutions also lack the performance to be able to serve as effective replacements for a graphics workstation. Scientists, researchers, and engineers in fields such as biosciences, energy exploration, and mechanical design rely on heavily interactive 3D applications as part of their daily workflow. These applications generally can only achieve usable performance if the 3D rendering is hardware-accelerated. Thus, organizations that would like to move toward a more centralized, managed model of application deployment have been constrained by their inability to move key 3D applications off of the user's desktop. The Old School Approach: Indirect RenderingThe problem of how to remotely display a 3D application with hardware-accelerated rendering is a thorny one. 3D applications that are built on Unix or Linux typically use the OpenGL application programming interface (API) to do the actual 3D rendering and the GLX API to manage the relationships between OpenGL rendering contexts and application windows. GLX is an extension to the X Window System ("X" or "X11") protocol, and it can take advantage of that protocol's inherent remote display capabilities. In this mode of operation, referred to as "indirect rendering", the OpenGL commands are encapsulated inside of the X11 protocol stream and sent to an X server running on a remote machine. The X server then passes the OpenGL commands to the local 3D rendering system, which may or may not be hardware-accelerated (Figure 1.) So, the 3D rendering is still occurring on the user's desktop machine, even though the application is actually running on a machine located elsewhere. 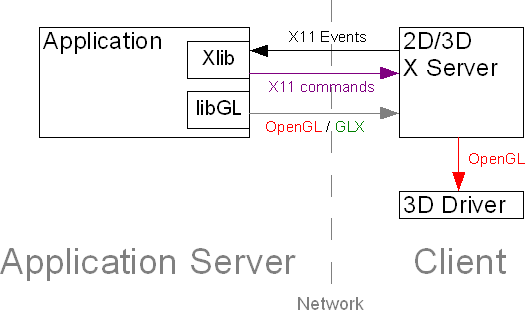 FIGURE 1: Indirect OpenGL Rendering Using GLX This works OK (not great) if the data being rendered is small and static, if display lists are used, and if the network has high bandwidth and low latency. For a variety of reasons, though, most applications do not use display lists. In some cases, the application programmers simply did not envision the application being displayed remotely, but usually an application avoids display lists because they are not suitable for the particular type of rendering that the application does. Many applications generate geometry dynamically, making display lists useless. Still others deal in large geometries, for which the overhead of building the display list on even a local display is undesirable. If display lists are not used in an indirect rendering environment, then every vertex call has to be passed over the network as every frame is rendered. This could amount to millions of little packets of information being sent over the network just to render one frame. In this case, the application performance will be bound by the latency of the network connection, and even on the fastest networks, rendering geometries of any significant size will quickly become an untenable proposition. The situation becomes even worse when textures enter the picture. Imagine passing a planar probe through a multi-gigavoxel volumetric dataset such as the Visible Human. The probe will be at least 1 megavoxel in size, meaning that the textures mapped to that probe will occupy at least 3 Megabytes. These textures have to be regenerated on every frame with no reuse of texture data from frame to frame. So, whereas network latency is not as much of an issue in this case, bandwidth definitely is an issue. Even in the best case, a gigabit connection would be required to get anything close to a usable frame rate. To further complicate matters, certain OpenGL extensions do not work in an indirect rendering environment. Some of these extensions require the ability to directly access the 3D graphics hardware (GPU) and thus can never be made to work across a network. In other cases, either the server's OpenGL library or the client's X server do not provide explicit support for the extension, or the extension relies on a specific hardware configuration that is not present on the client machine. Also, it goes without saying that, since the client must perform the 3D rendering, it must have a 3D accelerator and a decent amount of computing power. Thus, indirect OpenGL rendering does little to centralize an organization's computing resources. Indirect OpenGL rendering might best be termed "welterweight client", since the client is not really heavy but not really thin either. Server-Side 3D RenderingWe begin to see that it is desirable for the 3D rendering to be performed on the server machine, where there is a fast and direct link between compute, graphics, and storage resources. If the 3D rendering occurs on the server, then only the resulting 2D images must be sent to the client. Images can be delivered at the same frame rate regardless of how big the 3D data was that was used to generate them. So, performing 3D rendering on the server effectively converts the 3D performance problem into a 2D performance problem. The problem then becomes how to stream 1-2 megapixels of image data over a network at interactive frame rates, but this problem is already addressed by a variety of commodity technologies (HDTV, to name one.) There are generally only two approaches that have been used to implement server-side OpenGL rendering with hardware acceleration:
Screen ScrapingWith the screen scraping approach, a separate application (the "screen scraper") runs on the server machine and monitors its display for events (such as window expose events) that might cause the pixels in the display to change. As such events occur, the screen scraper reads back the affected regions of the display from the frame buffer, compresses them, and sends the compressed images to all connected clients. Conceptually, this is the same approach used by a host of off-the-shelf 2D remote display packages, including the Windows version of VNC. However, such software packages generally do not work with hardware-accelerated 3D. The reason is that 3D accelerators use "direct rendering" to send OpenGL commands directly to the 3D hardware (GPU), thus bypassing the windowing system (Figure 2.) 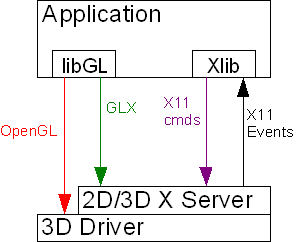 FIGURE 2: Direct OpenGL Rendering in an X Environment The screen scraper would normally monitor the X server to determine when pixels in the display have changed, but when direct rendering is used, the X server is never informed of changes to the content of OpenGL windows. The OpenGL-rendered pixels go straight to the frame buffer, so neither the X server nor the screen scraper knows when a 3D application has finished rendering a frame. The upshot of this is that 3D applications often appear as solid black windows when run inside a screen scraper. One solution is for the screen scraper to asynchronously read back the entire framebuffer on a periodic basis, compare the current screen snapshot against the last, and send the differences to all connected clients. x11vnc, for instance, uses this approach. An improvement upon this methodology would be to implement an inter-process communication mechanism to allow direct-rendered 3D applications to tell the screen scraper when the OpenGL region of a particular window has been updated. This would produce an architecture similar to Figure 3 and would eliminate the need for asynchronous polling of the display. 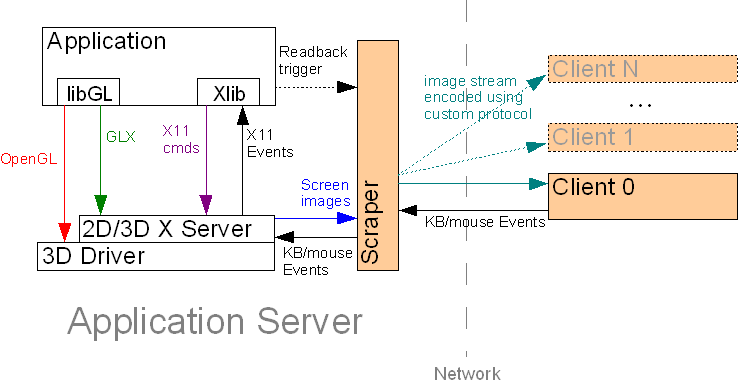 FIGURE 3: Screen Scraping with Direct Rendering There is one problem with this, however: how exactly is the readback trigger generated? In reality, additional software is required to interface between the application and the screen scraper. This additional software would monitor the application for certain function calls (such as A viable remote 3D solution is certainly possible using this approach, but screen scraping still has other drawbacks, the most onerous being that it is not a multi-user solution. While other users can share the same view of the server's display, they cannot use the machine to run other applications at the same time. Screen scraping is thus useful for accessing one's 3D workstation remotely, but it does not really solve the problem of delivering 3D applications as on-demand services. GLX ForkingThe idea of GLX forking, AKA "split rendering", has been around for a few years, and the definitive paper describing the approach was published by Stegmaier, Magallon, and Ertl (hereafter S/M/E) in the proceedings of the joint EuroGraphics/IEEE Symposium on Visualization, 2002. In a nutshell, GLX forking involves rerouting GLX commands from the application to a hardware-accelerated "3D X server" while allowing the rest of the X protocol stream to continue on to its original destination (the "2D X server.") GLX forking can generally be accomplished in two ways:
Method 1 involves an architecture very similar to Xvnc (the VNC X server), in which each user has their own personal "virtual" X display ("X proxy.") Unlike many implementations of Xvnc, however, this X proxy supports the GLX extension and can thus be used to display 3D applications. The 3D applications use indirect OpenGL rendering to send OpenGL commands to the X proxy, which then performs GLX forking as described by S/M/E to re-route all of the GLX commands to the 3D X server (Figure 4.) 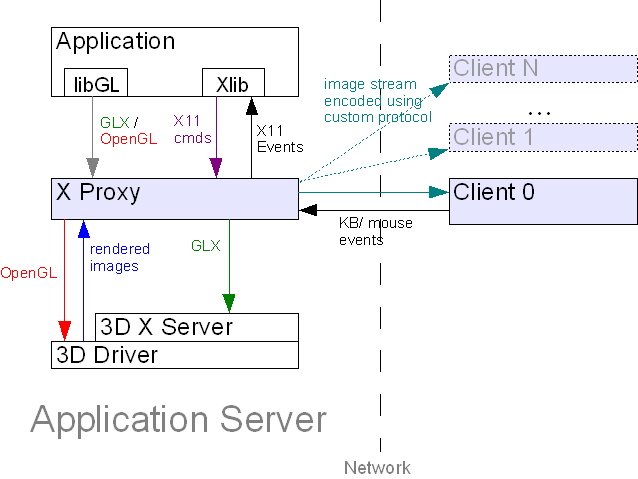 FIGURE 4: Out-of-Process GLX Forking Essentially, this is just a combination of indirect OpenGL rendering (Figure 1), a VNC-style X proxy architecture, and GLX forking. In this case, the X proxy acts as the GLX forker, marshaling GLX commands to the 3D X server while handling 2D drawing commands itself. Once an OpenGL rendering context has been established through the 3D X server, direct rendering can be used to send subsequent OpenGL commands directly from the X proxy to the 3D hardware (GPU.) At the end of every frame, the X proxy reads back the rendered images directly from the 3D hardware and composites them into the appropriate X window. Since the X proxy is in charge of marshaling 3D commands, it knows exactly when a 3D window has been updated, even though direct rendering was used to generate the pixels in that window. The major problem with the above approach is that the application must still use indirect OpenGL rendering to send 3D commands and data to the X proxy. It is, of course, much faster to use indirect rendering over a local socket rather than a remote socket, but there is still some overhead involved. Also, to ensure maximum compatibility, the X proxy must explicitly handle all OpenGL commands, including esoteric OpenGL extensions. OpenGL changes a lot more quickly than GLX, and this approach requires that the developer keep on top of those changes. However, per S/M/E, if the application is dynamically linked with an OpenGL shared library, then a "GLX interposer" library can be inserted into the application process at run time using 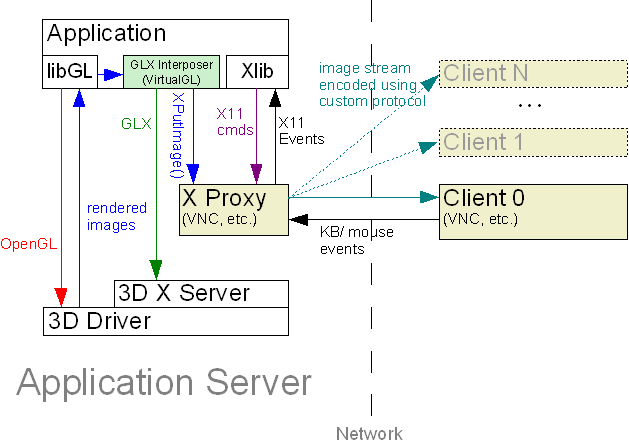 FIGURE 5: In-Process GLX Forking with an X Proxy Apart from marshaling GLX commands and managing Pbuffers, the GLX interposer must also read back the rendered pixels at the appropriate time (which is usually determined by monitoring The use of an X proxy is architecturally ideal, since it supports multiple sessions on a single server as well as multiple clients for each session. However, the reality is that most off-the-shelf X proxies do not perform well with 3D image workloads. For the most part, they are tuned to handle applications with large areas of solid color, few colors, and few inter-frame differences. 3D applications, on the other hand, generate images with fine-grained, complex color patterns and much less correlation between subsequent frames. The workload generated by drawing rendered 3D images into an X window is more similar to the workload generated by a full-screen video player, and those who are familiar with VNC and its ilk know that these off-the-shelf X proxies are not very good for playing videos. This is largely due to the lack of sufficient image compression/encoding performance. An additional drawback of most X proxies is the lack of seamless windows. Rather than each application window appearing as a separate client window, the user must interact with the entire remote desktop in a single window. VirtualGL addresses these issues in two ways:
The VGL TransportWhen using the VGL Transport, VirtualGL's GLX interposer encodes or compresses the rendered 3D images inside of the application process and sends the encoded images through a dedicated TCP socket to a VirtualGL Client application running on the client machine (Figure 6.) The VirtualGL Client is responsible for decoding the images and re-compositing the pixels into the appropriate X window. Meanwhile, the 2D elements of the application's GUI are sent over the network using the standard remote X11 protocol. Since their original paper, S/M/E's remote rendering solution has been modified to include an architecture similar to the VGL Transport (see: "Widening the Remote Visualization Bottleneck", ISPA 2003.) Examples of this architecture exist in industry as well. FIGURE 6: The VGL Transport: In-Process GLX Forking and Image Encoding This approach definitely has drawbacks. It requires that an X server be present on the client machine, and it can be somewhat sensitive to network latency due to its reliance on the chatty X protocol for rendering the 2D elements of the application's GUI. Additionally, the VGL Transport does not inherently support collaboration (multiple clients per session), since the images are being pushed to the client rather than pulled from the server. In order to collaborate with a user who is using the VGL Transport, a separate screen scraper (such as WebEx, NetMeeting, x11vnc, etc.) must be installed on the client machine. The primary advantage of the VGL Transport is that it provides a completely seamless application experience -- every application window appears as a separate window on the user's desktop. The VGL Transport can also send stereo image pairs, which allows true quad-buffered stereo to be used in a remote display environment. TurboVNCTurboVNC was developed to address the performance limitations of off-the-shelf VNC implementations and to provide an architecture more like that shown in Figure 5. TurboVNC performs server-side X11 rendering, and thus it lacks seamless windows and will generally require a bit more server CPU time than the VGL Transport. However, performing X11 rendering on the server also means that only images are sent to the client, and thus TurboVNC performs very well on high-latency, low-bandwidth networks. TurboVNC is based on TightVNC and borrows part of TightVNC's hybrid image encoding scheme, allowing it to use the most efficient image encoding method for each individual tile. TurboVNC also provides built-in collaboration capabilities, the ability to automatically send a lossless copy of the 3D pixels during periods of inactivity, fully configurable full-screen/multi-screen support, and more. Despite the lack of seamless windows, the other advantages of TurboVNC outweigh those of the VGL Transport, so most users prefer to use VirtualGL with TurboVNC. For more information on TurboVNC, visit www.TurboVNC.org. EGLThe EGL API, along with the |
 | All content on this web site is licensed under the Creative Commons Attribution 2.5 License. Any works containing material derived from this web site must cite The VirtualGL Project as the source of the material and list the current URL for the VirtualGL web site. |